How do databases recover from failure?

In today's fast-paced and data-driven world, a reliable and robust database is essential for any business or organization. Unfortunately, database failures can occur due to a variety of reasons, such as hardware failures, software bugs, or human error. The impact of a database failure can be severe, causing lost revenue, customer dissatisfaction, and reputational damage. In this blog, we will discuss one of the most widely used recovery techniques called Log-Based Recovery.
Well, first let's discuss what is
What is Log-Based recovery?
Log-based recovery is a technique used to ensure data consistency and integrity in the event of a database failure. By using a log of all the transactions that have occurred on the database, log-based recovery allows for a precise and efficient recovery process that can minimize the impact of a failure and get your database back up and running as quickly as possible.
Now, let's dive deeper
What are logs?
To put it simply, logs are just a sequence of records, recording all activities. An update log has (generally) three fields
Transaction Identifier: Unique identifier of the transaction that performed the write operation.
Data item identifier: Unique identifier of the location of the disk where the new data item was written.
Old value: Value of the data item before the update.
New value: Value of the updated data item.
Recovery after system crashes
A transaction is always atomic, which means the transaction is either executed completely or rollback. A transaction is never executed partially. So after the system is online our recovery mechanism must detect which transactions were completed and which weren’t. It must redo the ones that were completed and undo the incomplete ones.
Before we jump into the process, here are some important bits of information
Here, we are considering databases that use deferred modification. All the modifications are stored in memory and only flushed to the database once the transactions are committed.
[T(i), start] indicates the start of the transaction
[T(i), end] indicates the end of the transaction
Format for each update/write statement in the transaction will be [T(i), X(j), old_val, new_val]
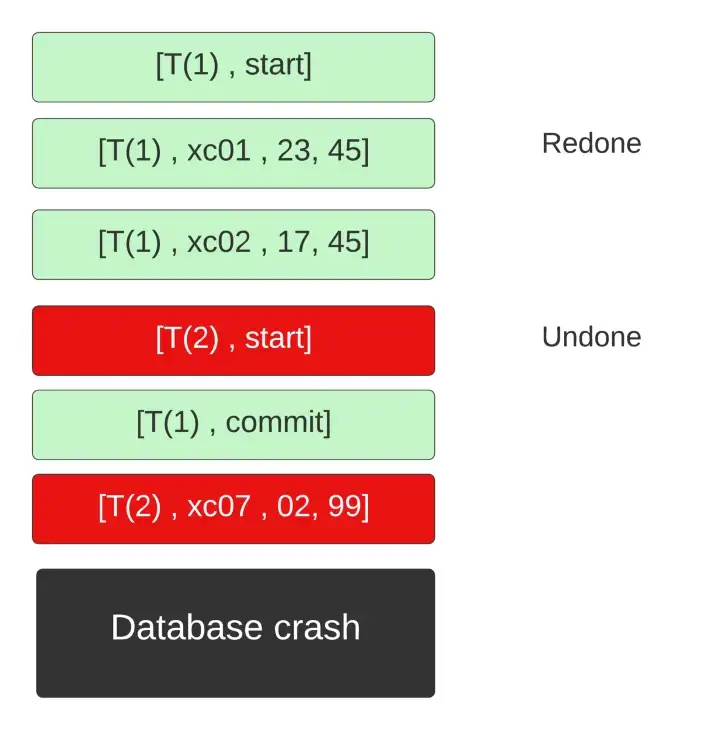
Phase 1: Redo Phase
We will go through the logs in the order in which they were carried out.
When we encounter a [T(i), start], we add T(i) to undo list. (Keep this one in mind.)
When we encounter a log [T(i), X(j), old_val, new_val] we write new_val to X(j).
When we encounter a log [T(i), end] we remove T(i) from the undo list.
If the transaction was completed, then all queries in it were redone. But in the process, we might have also redone queries from incomplete transactions. So how are we going to handle it? Well to handle that case we have a second phase.
Phase 2: Undo Phase
In this phase, we will go through the logs backward.
When we encounter a log [T(i), X(j), old_val, new_val], we check our undo list. If T(i) is present in the list we write old_val to X(j) basically undoing the operation done by the redo phase.
When we encounter the log [T(i), start], we remove T(i) from the undo list and add [T(i), abort] at the end of the log.
It is terminated after all action has been performed.
Optimizing Recovery Process
Did you notice any problem with this approach? Yes, every time there is a failure we have to perform the recovery algorithm on the entire log. But we can optimize this using Checkpoint.
To explain it simply, a checkpoint makes all the changes before it is permanent i.e., it writes all the updates to the disk and flushes all the data in the main memory to stable storage. It is also important to note that while the checkpoint is doing this no transactions are allowed to make write/update operations. So now instead of performing our recovery algorithm on the entire logs, we will start it from the latest checkpoint. A checkpoint is in the format [Checkpoint, L] where L represents Logs before the checkpoint.
But you might be thinking why do we need the L? Well, consider a case, where a transaction starts before Checkpoint but then aborts after the checkpoint. In that case, we need to roll back that transaction. The rest of the transactions that were committed can be erased to reduce occupied space.
What if we lose logs during a system crash, then we cannot redo or undo operations?
Well, this is where the concept of stable storage comes into play. How it works is beyond the scope of this article but in short, it replicates data in regular intervals to different non-volatile storage with independent failure recovery modes.
Credits for cover image: Image by pch. vector on Freepik



